Trojan Source Attacks
I was reading through this week’s Hive Five security newsletter and found the article on Trojan Source Attacks really interesting.
Research by Nicholas Boucher and Ross Anderson shows a new way to hide malicious code in plain sight: the source code that’s rendered doesn’t reflect its true functionality when run!
How?
Languages like English and Italian are written and read from left to right. Others like Hebrew and Arabic are the opposite: right to left.
When a Unicode document contains both kinds of text, special control characters are used to tell the code editor which direction to render in. This is specified in the Unicode Bidirectional or ‘Bidi’ algorithm. Some relevant command characters are shown below:

Examples
The paper provides POCs for several languages, and you can find them in the corresponding GitHub repo. I’ll go over a couple of Python examples from that repo to illustrate the idea.
Commenting out
The first example shows how comments and reordering have been used to create unexpected behaviour. Here is a simple script, opened in the latest version of VS Code:

Ok, so…. the colour coding tells us there’s something fishy going on, but the expected behaviour purely from the code is that when it’s run, you should see no output. Instead, here’s what we get:

And here’s what’s really going on in the script:

The blue pair of control characters preserves the comment in a Left-to-Right chunk, and the red RLO (Right-Left-Override) pushes that chunk to the right of the line when it is rendered. However, the interpreted code checks only that access_level is not equal to 'none', and the rest is commented out at runtime.
This behaviour is totally different to what a code reviewer would expect from inspecting the code alone.
Homoglyph functions
Another way to confound expectations is to use homoglyphs, i.e. different characters that look the same to a human observer. For example, here’s another script, viewed in VS Code:
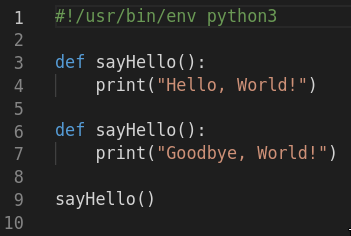
On first glance, it looks like we’ve created two functions with the same name, so we should get an error when we try to run it. But, it does in fact run and we get the following output:

If we open the file in hexedit, we can see what’s happening:

The first sayHello() function is written using the standard alphabet, whereas the apparent H in the second sayHello() function is actually hex D0 9D, the Cyrillic character EN, which just happens to look exactly like an upper-case H in the Roman alphabet. It’s this second function that’s called in the script, resulting in the output Goodbye, World!
Again, a completely unexpected behaviour from manual code review alone.
Defenses
The researchers suggest the simple solution of banning all unterminated Bidi override characters in strings and comments. This would allow for their legitimate use in Right-to-Left languages, while blocking malicious logic alteration.
Build pipelines should include scans for these kinds of patterns, and code editors should clearly display their presence instead of just following their direction.
Payloads
The following are URL encoded payloads for web app testing, plus links to other encodings:
- L to R Embedding:
%E2%80%AA - R to L Embedding:
%E2%80%AB - L to R Override:
%E2%80%AD - R to L Override:
%E2%80%AE - L to R Isolate:
%E2%81%A6 - R to L Isolate:
%E2%81%A7 - First Strong Isolate:
%E2%81%A8 - Pop Directional Formatting:
%E2%80%AC - Pop Directional Isolate:
%E2%81%A9