Fuzzing with AFL
Notes on this lecture by Erlend Oftedal. It’s a clear and concise walkthrough of getting started with AFL.
AFL - American Fuzzy Lop, developed by Michael Zalewski (@lcamtuf)
It’s open source, optimised and smart.
Workflow
- Compile the binary with AFL
- Find a test corpus
- Run the fuzzer
- Triage the findings
- When compiling, add
AFL_HARDEN=1to add code hardening and find crashes quicker. - Find files from unit/integration tests and minimise the list of cases.
afl-cminminimises a list of files, andafl-tminminimises each test file. @@means it takes input from file, as you can also usestdin- Some useful options:
-m <megabytes>max memory usage-t <milliseconds>timeout for each run
The output folder structure includes crashes, hangs and queue. Within the crashes folder, you get a lot of files with an identifier, the exit signal, the source branch, what kind of operation it was doing and which bit it was working on.
To triage, compile again without afl, and run the test case with the normal executable. Could use an address or memory sanitizer. gdb goes well with a plugin called exploitable. At this point, you can also use tmin again to make the test case small.
afl-gotcpu checks the status of your cpu cores and lets you know which you can run fuzzers on. You can run a single fuzzer or a controller fuzzer and several agent fuzzers.
Runtime
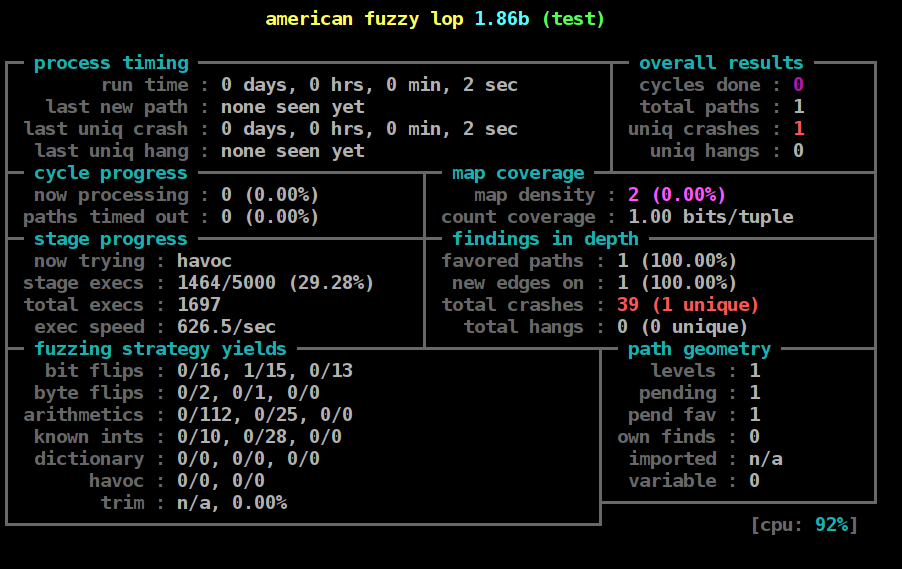 On the right of the output screen, you see the paths it is finding. If it doesn’t find paths, check to see if you are running the instrumented binary you compiled with afl.
On the right of the output screen, you see the paths it is finding. If it doesn’t find paths, check to see if you are running the instrumented binary you compiled with afl.
last new path is in the top left - if this keeps incrementing, it could be due to the same problem, or that you have found all the paths.
On the left, you see the strategies used, and which ones yielded new paths. The strategies are bit flips, byte flips, arithmetics, known ints, dictionary, havoc and trim.
In the top right, cycles done shows how many times it has run through all the paths found. You should wait until the controller fuzzer has done 5 or 10 cycles before stopping the fuzzer. The agent fuzzers will do many more cycles.
afl-whatsup <output folder> lets you see the output for each fuzzer all in one screen.
Optimisations
The goals are execution speed and fail fast.
Execution speed
Use cmin and tmin as previously mentioned to minimise the initial test cases. Isolate the code you want to test. Just break out the focused code and write a wrapper around it.
LLVM - Deferred instrumentation
LLVM mode comes with some clever methods. It will start the binary and find a point in time where it thinks it will start fuzzing from, then make a copy of itself so it doesn’t have to do the initialisation again and again. You can tell afl manually where this point it.
LLVM - Persistent mode
You can add a loop manually on a single process within the code:
while (__AFL_LOOP(1000)) {
/* Read input data */
/* Call library code to be fuzzed */
/* Reset state */
}
/* Exit normally */
libdislocator.so
A dropin for the libc allocator. Adds a guard page around any buffers to detect when read/write happens outside the expected bounds. However, this causes a lot of binaries to crash immediately. But it is useful for applications where it actually works.
Dictionaries
You can also add dictionaries so afl doesn’t have to discover everything itself. Examples here.
Triaging crashes
Check the crashes folder. In the README file, there is the command you used to launch the fuzzer. Choose a crash file and run it in gdb against the binary. There you should see the crash.
Then you can use exploitable.py available here by running source <path to exploitable.py> then exploitable within gdb. It will give you a short report on what happened and its potential severity. Of course, the severity depends on where the binary is running - if you are running it locally on a server, it might not be severe, but if it parses data coming in from a network, it could be way more critical.